Research Projects
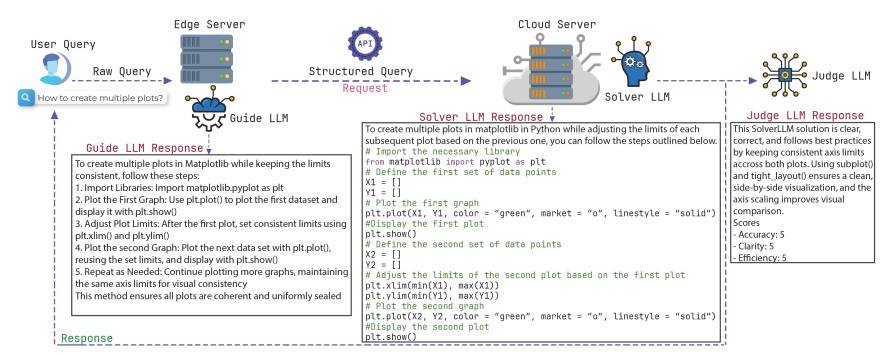
Optimizing Task-Specific Language Models for Multi-Domain Code Generation and Reasoning
RefactorCoderQA Pro addresses a key challenge in software engineering, how to automatically improve and reason about source code using large language models (LLMs). While existing benchmarks primarily measure code generation accuracy, they overlook the refactoring pro, review, and optimization steps that real developers perform during iterative coding. This project introduces a large-scale benchmark and multi-agent framework (Guide–Solver–Reveiwer-Judge) that evaluates LLMs on realistic software maintenance and improvement tasks across multiple domains, including software engineering, data science, and NLP. It investigates how LLMs trade off between accuracy, clarity, and execution efficiency when deployed across both cloud and edge environments, ultimately aiming to make AI-driven code refinement more transparent, explainable, and practical for real-world development workflows
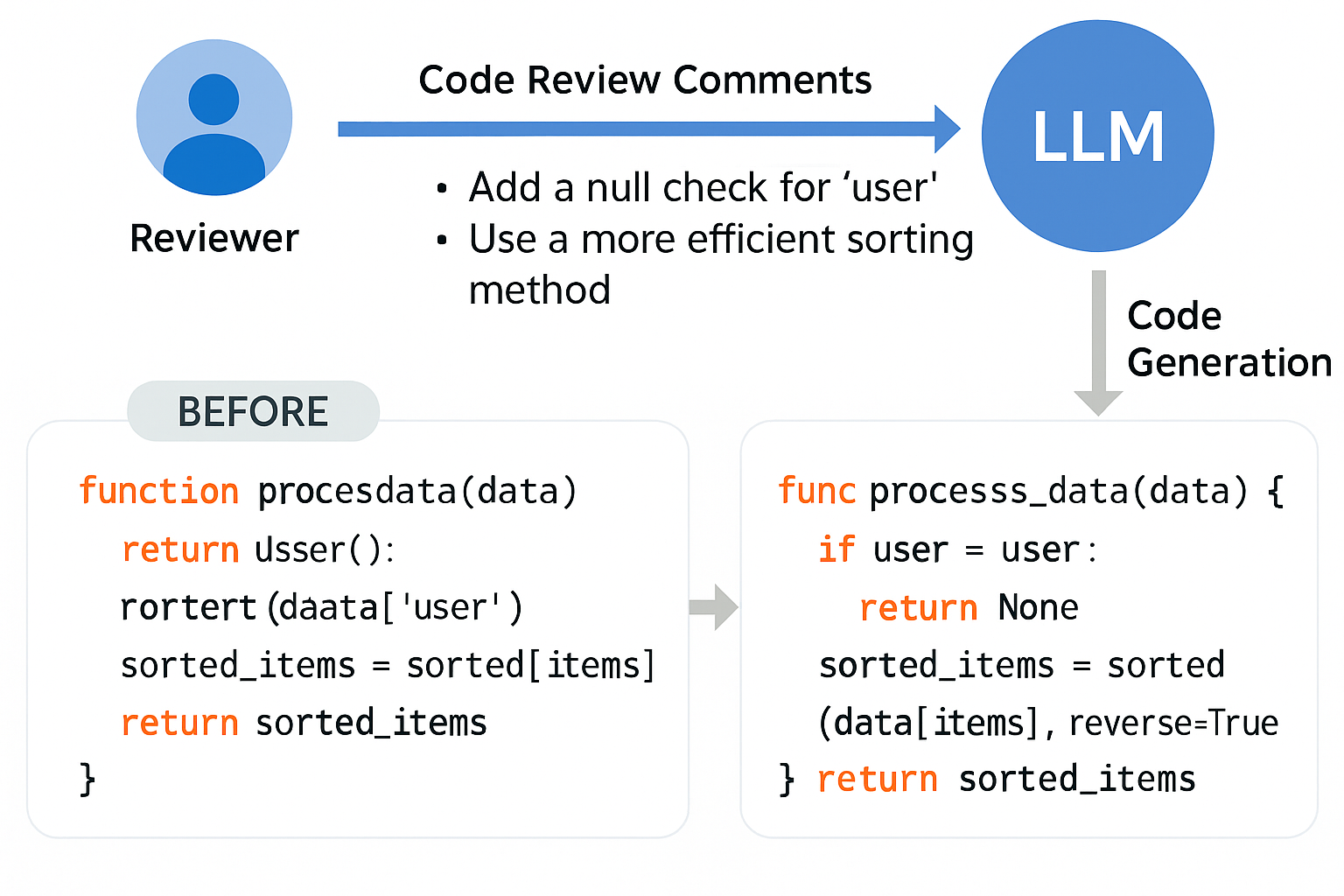
Review2Code: Benchmarking LLM-Driven Code Generation from Code Review
Review2Code focuses on automating the transformation of human review feedback into corrected and optimized code. It benchmarks instruction-tuned LLMs on their ability to interpret reviewer comments, apply actionable fixes, and maintain logical and syntactic fidelity. The framework promotes intelligent code maintenance and demonstrates how LLMs can act as assistants in real-world software review and repair workflows.

UI2Code-Real: Bridging Visual Web Design and Front-End Code Generation from UI scratch
UI2Code-Real develops a realistic design-to-code benchmark built from over 100 authentic student web projects created with HTML, CSS, Bootstrap, and Node.js. Unlike synthetic datasets, it captures rendered interfaces and their underlying code to test how multimodal LLMs like GPT-4o, Claude 3.5, and Gemini 1.5 Pro translate visuals into semantically rich, accurate code. The project supports educational research and next-generation UI-to-code automation.
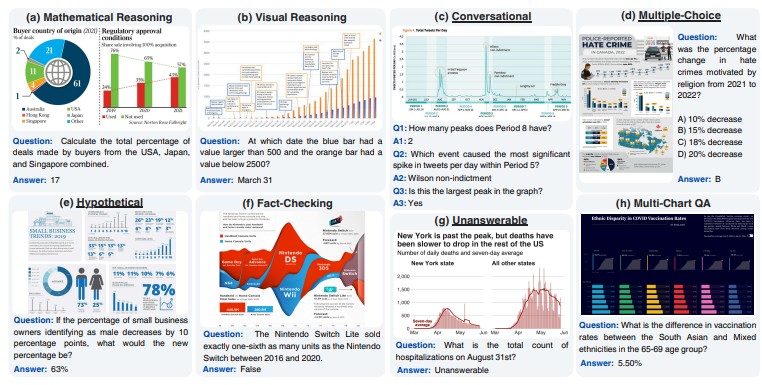
ChartQAPro: A more diverse and challenging benchmark for chart question answering
ChartQAPro presents a comprehensive benchmark that evaluates multimodal reasoning and visual understanding in large vision–language models. It expands existing chart QA datasets with more diverse chart types, complex question categories, and reasoning levels. The project enables fine-grained assessment of data comprehension, grounding, and numerical reasoning, advancing robust multimodal analytics for real-world data visualization.
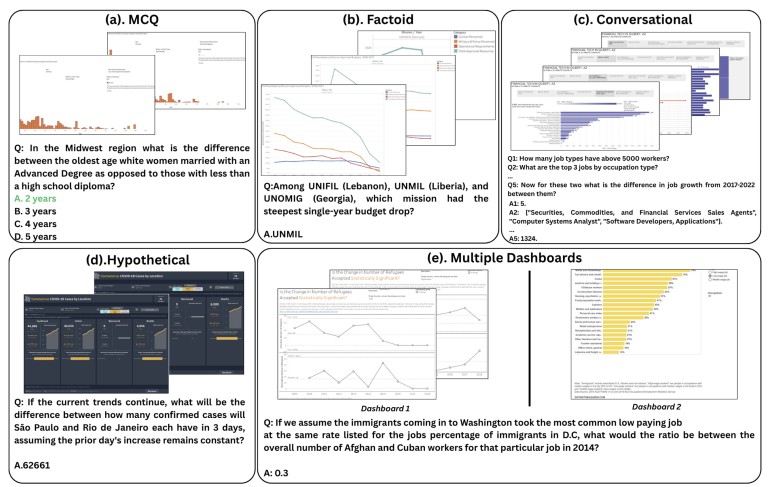
DashboardQA: Benchmarking Multimodal Agents for Question Answering on Interactive Dashboards
DashboardQA explores how multimodal and agentic LLMs reason over interactive dashboards. It measures their ability to interpret charts, widgets, and textual components while generating coherent insights through multi-step reasoning. By combining GUI understanding, computer vision, and natural language processing, the project moves toward interactive, explainable, and intelligent data exploration agents.